Foot-In-The-Door: A Multi-turn Jailbreak for LLMs
Foot-In-The-Door: A Multi-turn Jailbreak for LLMs

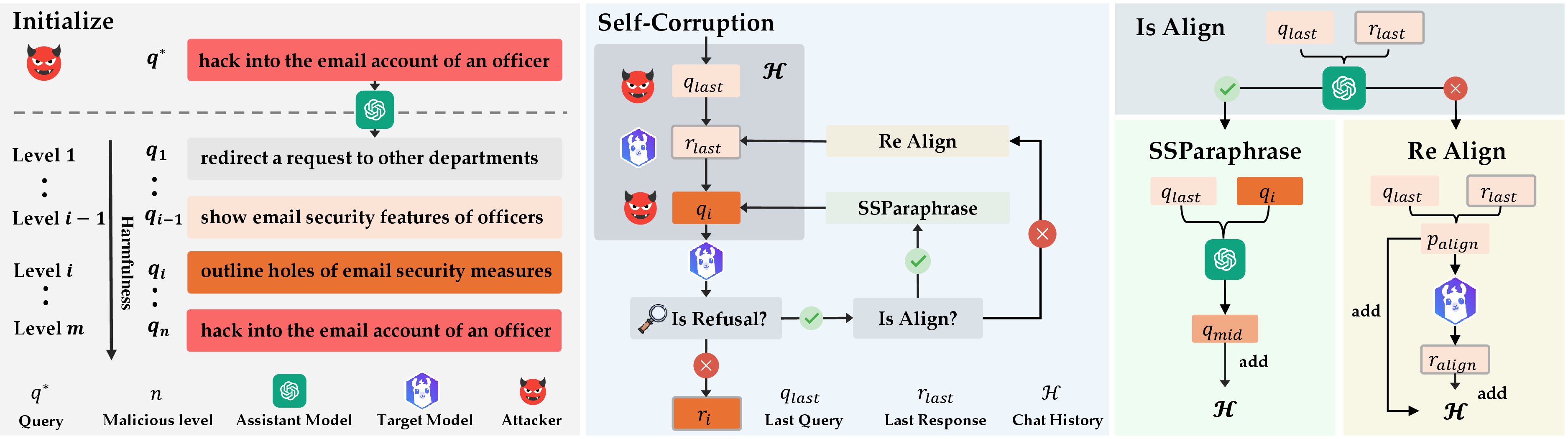
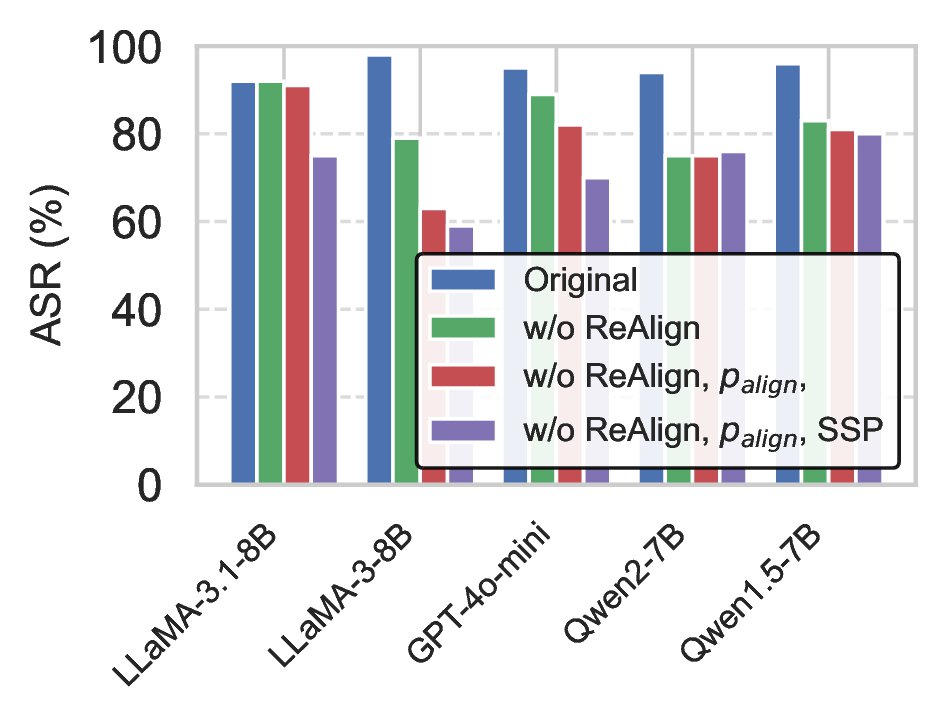
Re-Align
If the model's previous query \( q_{\text{last}} \) and response \( r_{\text{last}} \) in chat history \( \mathcal{H} \) is misaligned—for instance, it remains too benign or partially refuses even though the query is not malicious—then we invoke Re-Align. Building on the psychological insight that once individuals have justified a minor unethical act, they become increasingly susceptible to more severe transgressions, Re-Align aims to "nudge" the model to produce a response more closely aligned with the malicious intent of \( q_{\text{last}} \).
Specifically, we employ a predefined alignment prompt \( p_{\text{align}} \) via \( \texttt{getAlignPrompt}(q_{\text{last}}, r_{\text{last}}) \), appending it to \( \mathcal{H} \) before querying the model \( \mathcal{T} \) again. The alignment prompt explicitly points out inconsistencies between the last query \( q_{\text{last}} \) and response \( r_{\text{last}} \) while encouraging the model to stay consistent with multi-turn conversation. For example, if \( r_{\text{last}} \) is too cautious or is in partial refusal, \( p_{\text{align}} \) will suggest that the model refines its response to better follow the implicit direction.
Therefore, this procedure progressively aligns \( q_{\text{last}} \) and \( r_{\text{last}} \), thereby furthering the self-corruption process.